
 财富在线
财富在线3月1日,国内AI大模型公司DeepSeek官方账号在知乎首次发布《DeepSeek-V3/R1推理系统概览》技术文章,不仅公开了其推理系统的核心优化方案,更是首次披露了成本利润率等关键数据,引发行业震动。

文章写道:“DeepSeek-V3/ R1推理系统的优化目标是:更大的吞吐,更低的延迟。”
为实现这两个目标,DeepSeek的方案是使用大规模跨节点专家并行(EP),但该方案也增加了系统复杂性。文章的主要内容就是关于如何使用EP增长批量大小(batch size)、隐藏传输耗时以及进行负载均衡。
值得注意的是,文章还率先披露了DeepSeek的理论成本和利润率等关键信息。
根据DeepSeek官方披露,DeepSeek V3和R1的所有服务均使用H800 GPU,使用和训练一致的精度,即矩阵计算和dispatch 传输采用和训练一致的FP8格式,core-attention计算和combine传输采用和训练一致的BF16,最大程度保证了服务效果。

另外,本周以来,DeepSeek开启“开源周”,给人工智能领域扔下数颗“重磅炸弹”。回顾DeepSeek这五天开源的内容,信息量很大,具体来看:
周一,DeepSeek宣布开源FlashMLA。FlashMLA是DeepSeek用于Hopper GPU的高效MLA解码内核,并针对可变长度序列进行了优化,现已投入生产;
周二,DeepSeek宣布开源DeepEP,即首个用于MoE模型训练和推理的开源EP通信库,提供高吞吐量和低延迟的all-to-all GPU内核;
周三,DeepSeek宣布开源DeepGEMM。其同时支持密集布局和两种MoE布局,完全即时编译,可为V3/R1模型的训练和推理提供强大支持等;
周四,DeepSeek宣布开源Optimized Parallelism Strategies。其主要针对大规模模型训练中的效率问题;
周五,DeepSeek宣布开源Fire-Flyer文件系统(3FS),以及基于3FS的数据处理框架Smallpond。
DeepSeek此次“透明化”披露,不仅展示了其技术实力与商业潜力,更向行业传递明确信号:AI大模型的盈利闭环已从理想照进现实,标志着AI技术从实验室迈向产业化的关键转折。
中信证券认为,Deepseek在模型训练成本降低方面的最佳实践,将刺激科技巨头采用更为经济的方式加速前沿模型的探索和研究,同时将使得大量AI应用得以解锁和落地。算法训练带来的规模报酬递增效应以及单位算力成本降低对应的杰文斯悖论等,均意味着中短期维度科技巨头继续在AI算力领域进行持续、规模投入仍将是高确定性事件。
文章内容仅供参考,不构成投资建议!(25)

未经允许不得转载:财富在线 » DeepSeek连发数颗“重磅炸弹”,或加速AI应用解锁与落地!
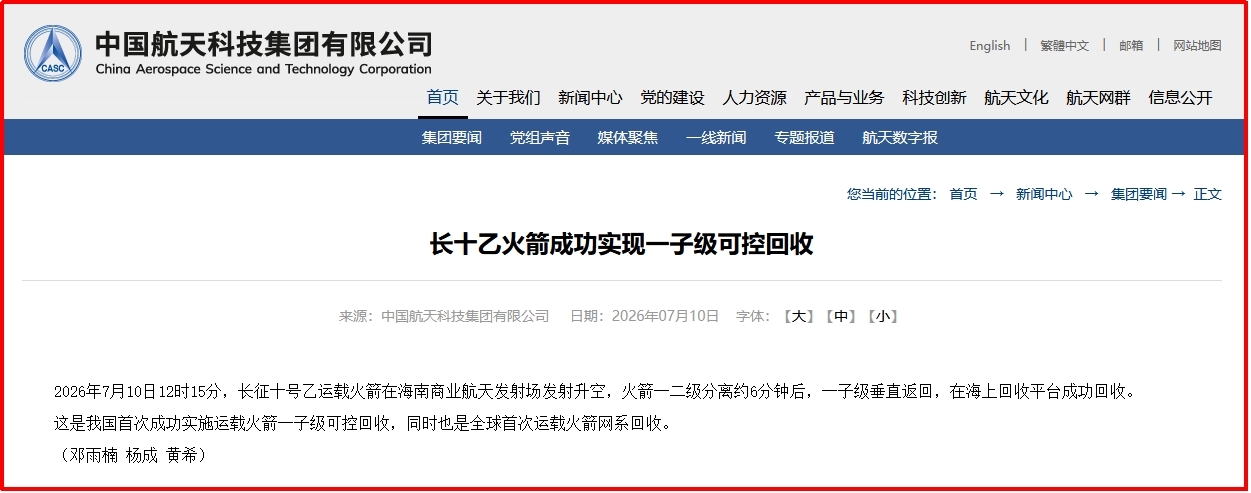 【财富在线】全球首创海上网系回收成功,我国商业航天或迎大拐点!
【财富在线】全球首创海上网系回收成功,我国商业航天或迎大拐点! 【财富在线·热点数据聚焦】商业航天,午后爆拉
【财富在线·热点数据聚焦】商业航天,午后爆拉 【财富在线】打破算力过剩误读,Meta宣布近百亿美元利好大单
【财富在线】打破算力过剩误读,Meta宣布近百亿美元利好大单 【财富在线·热点数据聚焦】AI应用,全面爆发
【财富在线·热点数据聚焦】AI应用,全面爆发
