
 财富在线
财富在线
经过长达一个多月的内测后,3月16日,国内首款对标ChatGPT的产品“文心一言”正式现身。
从现场氛围可见外界的期待。早在发布会正式开始前半小时,容量超百人的现场已几乎座无虚席。一天之前,OpenAI正式发布王炸产品GPT-4全面“秀肌肉”,人们都很好奇,百度的文心一言究竟是怎样的产品。

在文心一言的发布会现场,百度公司创始人、董事长兼CEO李彦宏坦言道。但他同时指出,文心一言对标着ChatGPT甚至GPT-4,门槛是很高的,“全球大厂还没有一个做出来的,百度是第一个。”
从发布会现场来看,通过在文学创作、商业文案创作、数理推算、中文理解、多模态生成五个使用场景中的能力展现,文心一言也确实在一定程度上具备对人类意图的理解能力,回答的准确性、逻辑性、流畅性也都逐渐接近人类水平。

例如,在文学创作场景中,李彦宏以著名科幻小说《三体》为例,围绕小说核心内容、内容续写提问文心一言,在几秒时间内,文心一言给出综合性强、内容提炼度高的回答;在数理推算能力展示中,文心一言对“鸡兔同笼”问题进行作答并纠正了题干给出的错误信息。

此外,文心一言还具备文本、图片、音频和视频的多模态生成能力,在音频方面甚至能够生成四川话等方言语音。“多模态是生成式AI一个明确的发展趋势。”李彦宏表示,“未来,随着百度多模态统一大模型的能力增强,文心一言的多模态生成能力也会不断提升。”

文心一言看似简单,其实背后具备很高的技术门槛。“能做应用题,意味着对长文本的理解能力要求很高,整体文生图、文生视频这些多模态生成能力也需要大量的技术积累。”
尽管目前暂无法与ChatGPT同日而语,但文心一言也有自己的优势。当前ChatGPT的强大是有目共睹的,但在中文领域ChatGPT的成熟度略低。浙江大学国际联合商学院数字经济与金融创新研究中心联席主任盘和林指出。事实上,作为高度本土化的生成式AI产品,文心一言更加匹配国内用户的中文使用习惯,表现出较高的中文语言和中国文化的理解能力。

对中文的准确理解,离不开高密度的中文数据训练。此前在接受21世纪经济报道记者采访时,IDC中国研究总监卢言霞认为,文心一言有中文语言优势,有国内领域相关数据积累。据了解,文心一言大模型的训练数据包括万亿级网页数据,数十亿搜索数据和图片数据,百亿级语音日均调用数据,及5500亿事实的知识图谱。

而另一则消息:北京时间3月15日凌晨,更强大恐怖的GPT-4正式发布了!OpenAI老板Sam Altman介绍GPT-4时直接这么形容:“这是我们迄今为止功能最强大的模型!”
到底有多强?根据OpenAI官方的介绍,GPT-4是一个“超大的多模态模型”,也就是说,它的输入不仅可以是文字,还可以是图像!

不少用户不眠不休测试GPT-4:有的用来出营销策划、写广告词;有的用于看图解答逻辑题、数学题;甚至还有用来调侃脑筋急转弯。GPT-4全都对答入流,并展示出强悍的处理能力,让用户直呼“强得离谱”、“牛啊牛啊”。

OpenAI推出的新一代多模态模型GPT-4.OpenAI表示,GPT-4是一个大型的多模型模型(接受图像和文本输入、输出文本)。相比于GPT-3.5,GPT-4进一步升级。OpenAl表示,新模型将产生更少的错误答案,更少地偏离谈话轨道,更少地谈论禁忌话题。虽然在许多现实场景中不如人类聪明,但在各种专业和学术基准测试中表现出人类水平的性能。例如GPT-4在模拟律师考试的成绩在考生中排名前10%左右,在SAT阅读考试中排名前7%左右。

ChatGPT的主要魅力在于,它利用从互联网获取的海量训练数据开展深度学习和强化学习。有研究预测,按照目前的发展速度,到2026年ChatGPT类大模型的训练将耗尽互联网上的可用文本数据,届时将没有新的训练数据可供使用。因此,算力瓶颈之外,训练数据将成为大模型产业化的最大掣肘之一。

以GPT系列为代表的大型语言模型(LLM)能教会机器以统计方式理解自然语言,完成此前人类进行的内容读取和理解。随着多模态带来的模型全面化,人工智能将向着拥有人类解释能力这一目标更进一步。
GPT-4可能成为生成式AI时代的“报晓鸟”,人类思维的“副手”。全要素生产率在PC时代飞速增长,在互联网普及后的增长速度略有放缓,而在生成式AI时代,全要素生产率可能会再次加速上升。

未经允许不得转载:财富在线 » 【热点跟踪】国产ChatGPT“第一枪”打响!逐浪会有时!
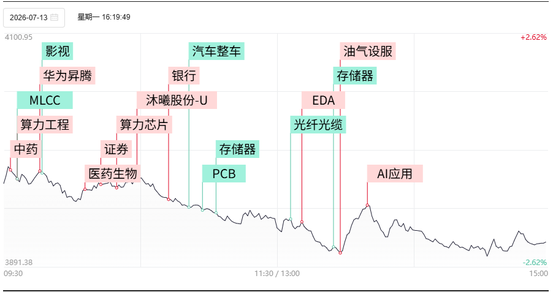 股市财富在线收评:结构性行情凸显,医药与科技局部爆发
股市财富在线收评:结构性行情凸显,医药与科技局部爆发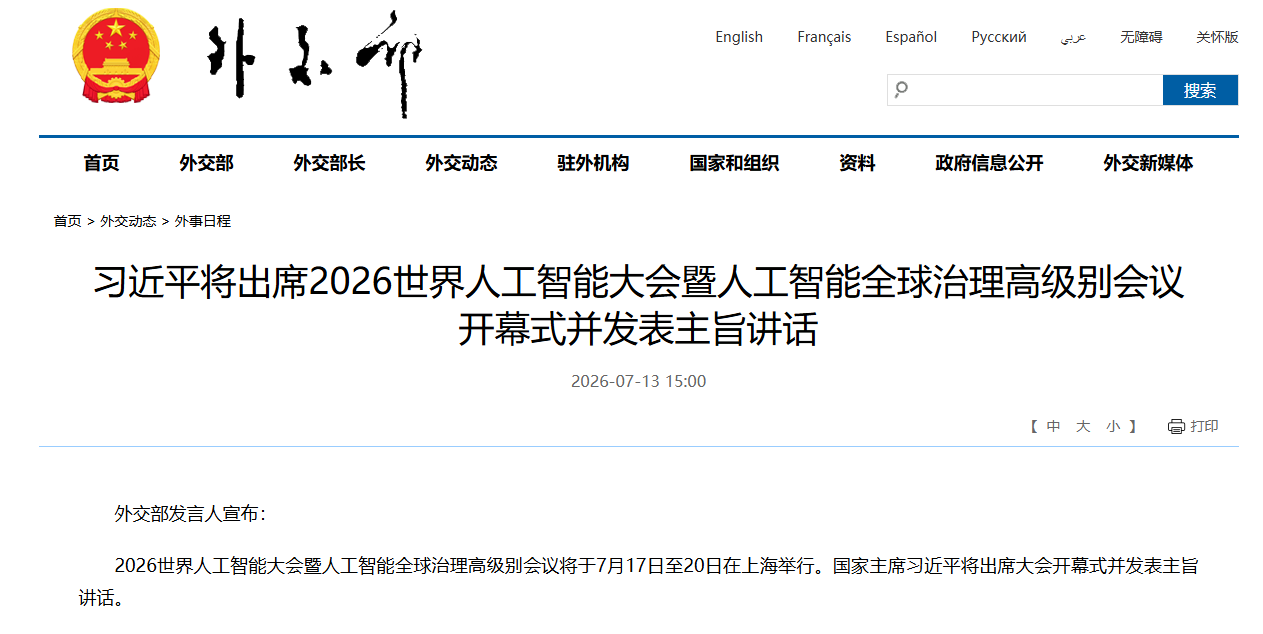 【财富在线】盘后大利好突袭,A股或修复上涨,AI应用行情有望徐徐展开
【财富在线】盘后大利好突袭,A股或修复上涨,AI应用行情有望徐徐展开 【财富在线·热点数据聚焦】创新药午后维持强势!行业国际化或加速进入兑现期
【财富在线·热点数据聚焦】创新药午后维持强势!行业国际化或加速进入兑现期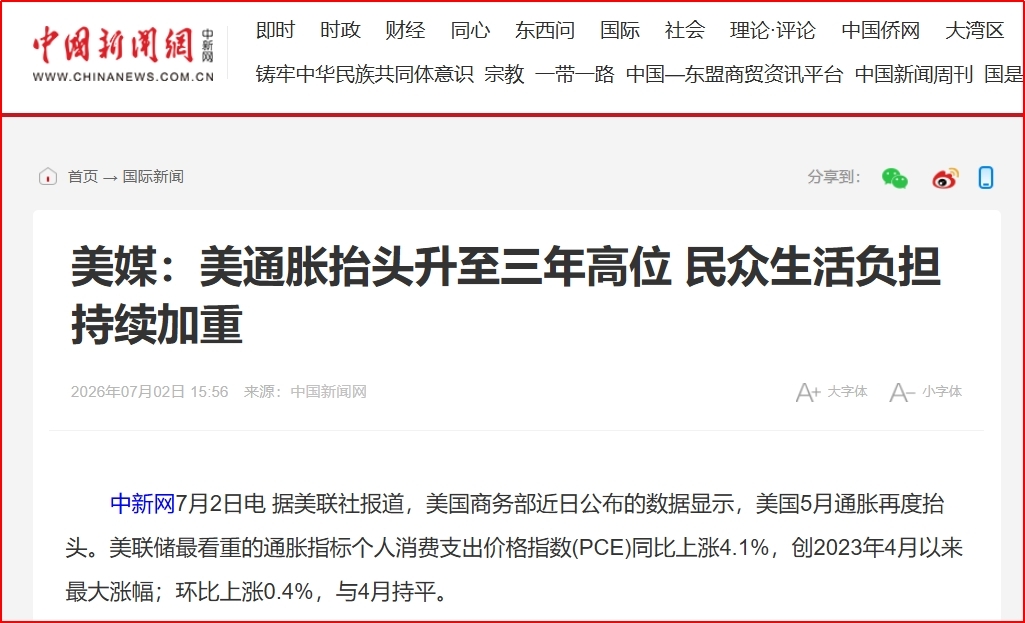 【财富在线】黄金为什么跌?未来走势,这几点是关键
【财富在线】黄金为什么跌?未来走势,这几点是关键
